

Introduction
Today’s technology-enabled businesses constantly produce and consume data in multiple ways. When it specifically comes to tabular data, relational databases have been at the core for storing and retrieving information in an efficient manner. But the caveat here is that querying a database with numerous tables that grow along with the large volumes of incoming data makes it a more cumbersome task to be accomplished. Particularly for everyday users within organizations who may not be extremely conversant with SQL language, intricate schemas and data models, it becomes more challenging to achieve data retrieval. Hence, we have set out to solve this problem by building a simple use-case for a large language model, enabling users to interact with databases in their day-to-day natural language. This approach not only reduces the effort of writing sql queries and debugging them, but also makes it easier for business users to get accurate results for SQL query generation. This helps the business to focus more on data driven decisions by reducing the time and effort spent on data retrieval itself
In this blog, we will explain a methodology for conversion of user’s natural language questions to SQL queries and view the outputs. To accomplish this task, we have employed state-of-the-art Generative AI LLM model from OpenAI. Additionally, we will address a few other concerns such as – API costs, token usage and Latency for query executions of the same.
How it works:
The user will provide natural language question with some metadata about the tables and columns but no data will be sent out to the API. The LLM understands the question and the context and generates the SQL query. The generated SQL query is executed locally on your databases to get the results. The data privacy issue is addressed by sending only the metadata but not sending any actual data. The token size is optimized by first identifying the right tables and then sending only metadata for relevant tables. The accuracy is maintained by testing them on some mock data and then iterating to rectify the errors in terms of syntax and data validation.
Technical Architecture:
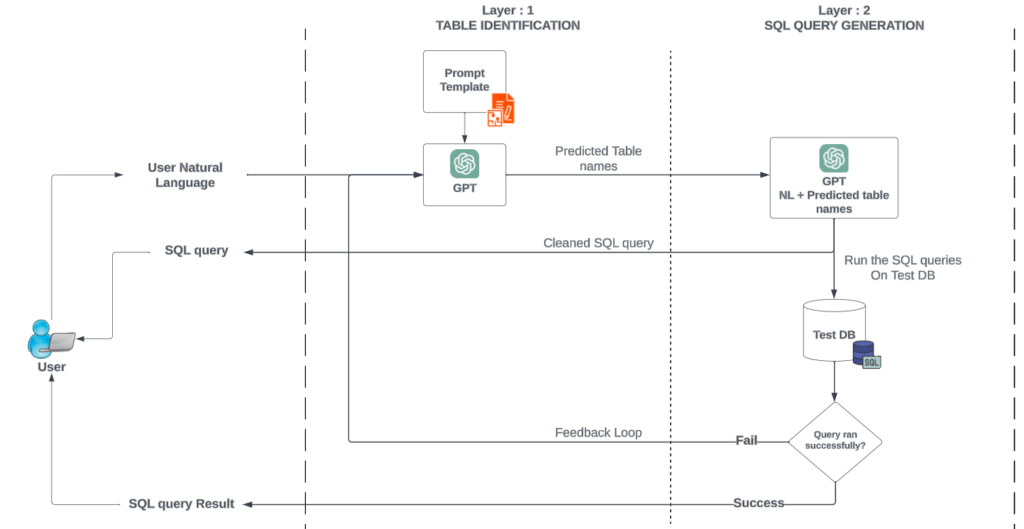
Some of the traditional approaches involve a simple NL to SQL program developed in order to only address the final problem statement of achieving the generated SQL query in an accurate way. However, the other components of latency as well as token usage might need additional optimization. To address the other two key points, we have considered a two layer approach.
Approach:
The first layer – “TABLE IDENTIFICATION” aims to identify the table names that most probably will be required. This approach is mainly to identify essential table names which would be needed for querying the database. For this, we consider the user’s natural language as input along with the prompt. The prompt template will consist of only the metadata (description of the table and its contents). This gives the LLM enough context to understand what are the right tables to be used for generating the query.
The second layer – “SQL GENERATION” consists of the predicted table names as the input and processed into the LLM along with the context and column metadata of the filtered tables only. The generated query can be validated against a TestDB with some mock data for correctness of the query. In case, the query result was successfully fetched, it can be viewed as output for the user. Else, a failed SQL query will be sent back to Layer 1 as a feedback loop and repeat the steps again to produce the results until the TestDB is able to execute the SQL query both in terms of syntax and correctness of the output.
Below is a simple comparison between the approach 1 where we ask the LLM to generate a query with all the context that we have and 2 where we only send the relevant/filtered context and then get the SQL query.
Comparison:
Accuracy and reproducibility are the key metrics of evaluation. But efficiency in terms of latency and cost is also crucial while building an enterprise level application. The simplest way of accomplishing Natural Language to SQL query generation is to send the entire metadata of database, tables and columns to GPT model as a prompt and then generate a SQL query. But this is not an efficient solution when dealing with large databases and tables. Here we have provided a comparison between the simplest approach and our optimized approach.
Let’s consider the below 3 NL to SQL queries for this comparison.
Natural Language Queries:
1.”What was the total number of invoices issued?”
2.”Get the Customer name and Email ID of those who are from France”
3.”Count the number of invoices issued in the year 2009″
The execution results of three queries based on the following parameters are:
1. Token Usage
Prompts that are sent to the GPT models are converted to tokens which are basically the root of the word and the cost of the API call is calculated based on the tokens consumed.
Token usage = Total Input tokens + Total output tokens
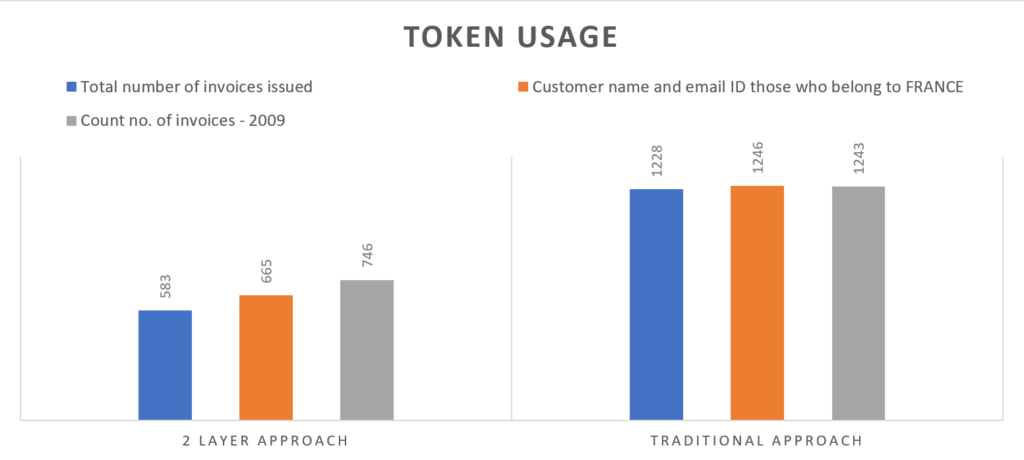
The number of tokens consumed in this two layer approach is almost 50% less.
2. API cost / pricing
The API cost is calculated based on the tokens consumed and the rate card of the specific model used. OpenAI GPT model pricing can be viewed here.
When building enterprise level NL to SQL solutions apart from accuracy and latency, pricing can also be a crucial factor.
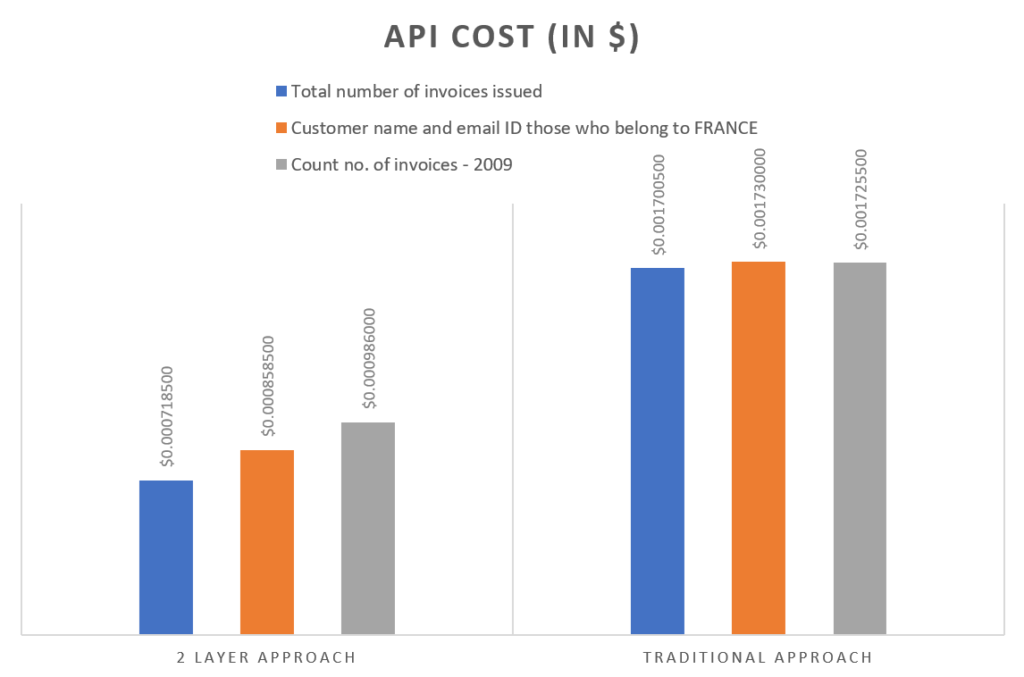
The above plot shows a significantly lesser API cost
3. Latency
Enterprise level applications are expected to be fast and accurate. This should hold good even when the volume of data increases steadily. Latency can be reduced by optimizing the prompt templates
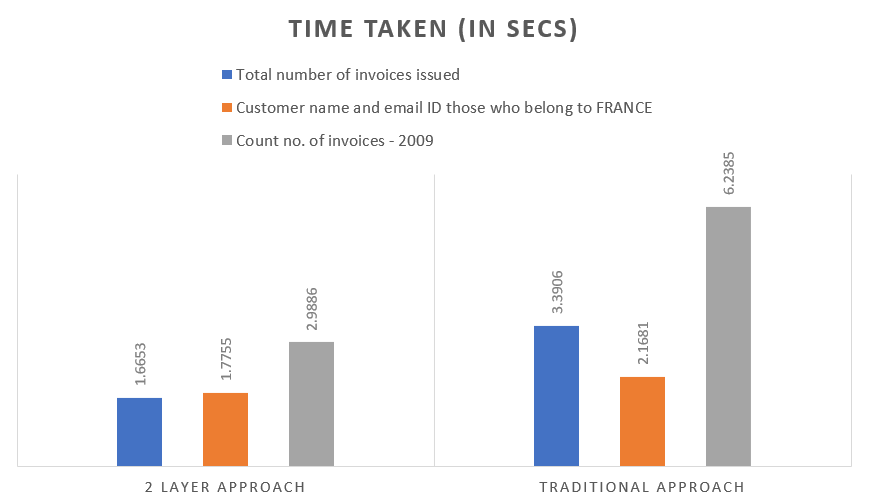
In the above bar graph, we can clearly visualize the difference between multiple simple queries (in seconds).
Potential Use cases:
- Automate reporting and visualizations
- Integration with ERP softwares to automate routines
- Interact with databases quickly and easily
Conclusion:
In this blog we have looked at an approach to generate SQL queries from natural language using the Generative AI capabilities of LLMs. We have looked at how we can address the data privacy, accuracy and cost optimization parts of the solution. At AIqwip we are building solutions powered by the Generative AI capabilities with the perspective of business adoption and value addition.